



В первой части серии мы разобрались, зачем маркетологам вообще нужен ComfyUI, потом поставили его на компьютер и научились работать с интерфейсом и готовыми шаблонами. В четвёртой статье мы уже правили чужие схемы под себя, не ломая весь workflow.
Теперь логичный шаг — посмотреть на базовый рабочий процесс «как под микроскопом» и понять, почему именно такой набор узлов идеально подходит для старта новичку.
Теперь логичный шаг — посмотреть на базовый рабочий процесс «как под микроскопом» и понять, почему именно такой набор узлов идеально подходит для старта новичку.
Создание простого шаблона в ComfyUI под txt2img
Для понимания того, как происходит работа шаблонов в ComfyUI, давайте разберем самую базовую задачу — генерация картинки по текстовому описанию, или txt2img.
Так как мы в этой статье ориентируемся на новичков, то возьмем самую простую модель, которая состоит из базовых узлов. Так сказать, ничего лишнего.
Так как мы в этой статье ориентируемся на новичков, то возьмем самую простую модель, которая состоит из базовых узлов. Так сказать, ничего лишнего.
Сейчас у нас в схеме есть такие ключевые блоки
- CheckpointLoaderSimple — загрузка основной модели.
- LoraLoader — загрузка LoRA‑стиля.
- KSampler — сам процесс генерации изображения.
- VAEDecode — превращение внутреннего представления в видимую картинку.
- PreviewImage — предварительный просмотр результата.
- EmptyLatentImage — определяет размер холста.
- CLIPTextEncode — два текстовых блока для запроса и анти‑запроса (Prompt / Negative).
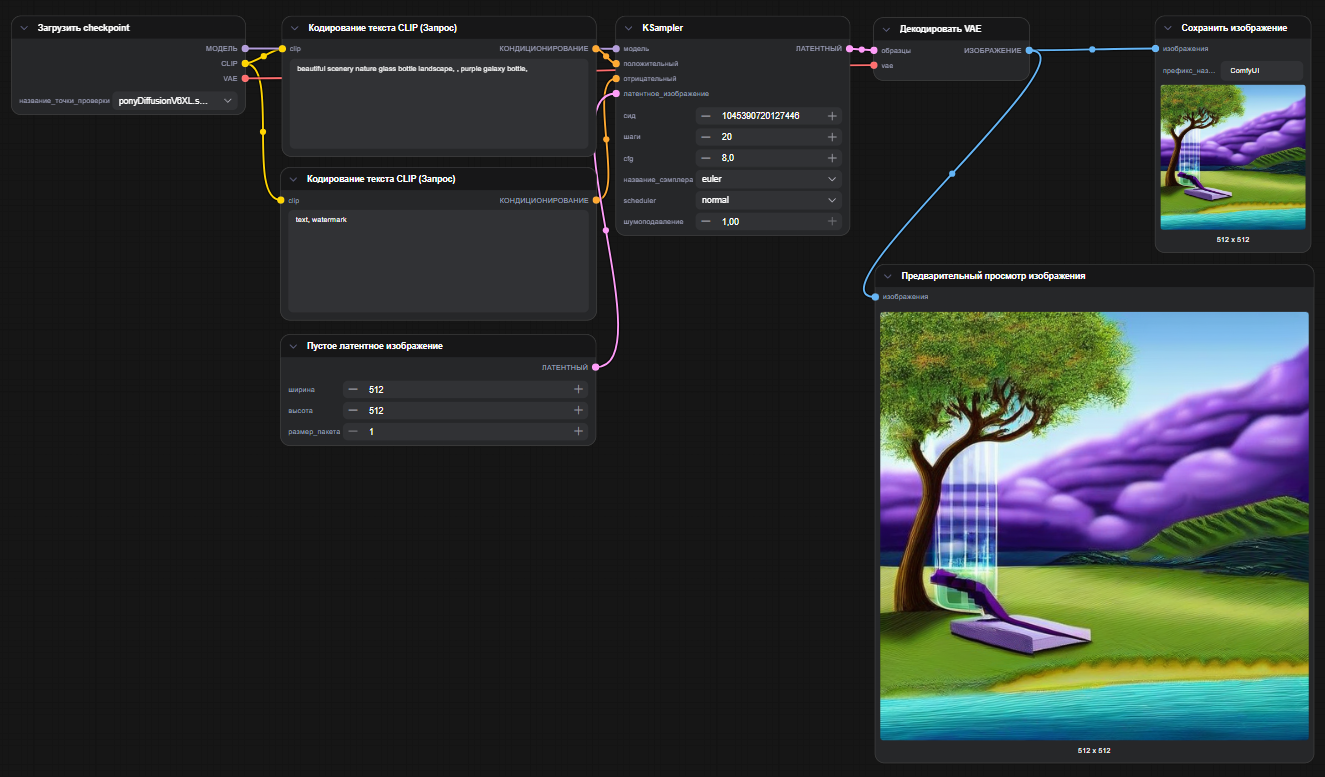
Главное достоинство такой схемы — она идёт по прямой: загрузили модель → задали текст и размер → прогнали через KSampler → декодировали → посмотрели результат.
Никаких развилок, запутанных ветвлений, пересечений и «магии». Новичку важно уловить именно этот путь слева направо, а не утонуть в сотне дополнительных опций.
Никаких развилок, запутанных ветвлений, пересечений и «магии». Новичку важно уловить именно этот путь слева направо, а не утонуть в сотне дополнительных опций.
Какие базовые идеи объясняет каждый узел
Давайте разберем каждый блок более детально, для того чтобы понять общий механизм работы шаблона.

Checkpoint Loader Simple
Это блок, который «подключает мозг» нейросети. Модель в ComfyUI — это набор настроек и знаний, по которым ИИ рисует картинку: одна модель лучше делает реализм, другая — аниме, третья — яркие иллюстрации. Без загруженной модели генерация просто не запустится.
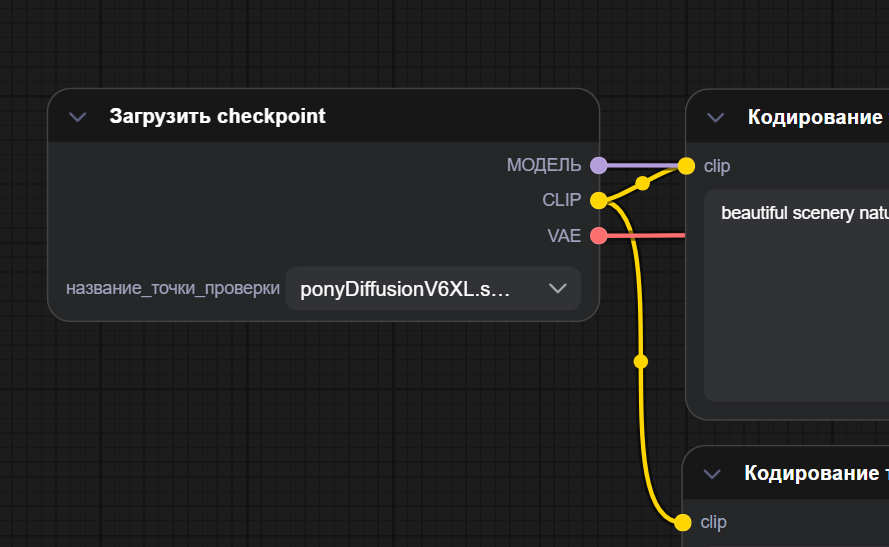

При первом выборе новой модели ComfyUI тратит время на загрузку её в память, это нормально
Дальше, после того, как нужная модель будет загружена и пока вы не закрыли программу или не сменили модель, этот шаг не повторяется — генерации идут заметно быстрее.
Lora Loader*
Данный блок, который добавляет к базовой модели «поведение по вкусу»: стиль, персонажа или конкретную манеру рисовки. То есть LoRA не заменяет основную модель, а слегка её подстраивает, как фильтр.
Одна LoRA делает кадр более мультяшным, другая — придаёт фирменный стиль бренда или повторяет внешний вид персонажа.
Одна LoRA делает кадр более мультяшным, другая — придаёт фирменный стиль бренда или повторяет внешний вид персонажа.
Для новичка это самый простой способ поэкспериментировать со стилем без скачивания тяжёлых моделей
Выбрали базовую модель в Checkpoint Loader Simple, затем через Lora Loader подключили нужную LoRA и сразу видите, как меняется итоговая картинка.
Соответственно данный блок опциональный, генерация может работать и без него.
Соответственно данный блок опциональный, генерация может работать и без него.
Empty Latent Image
Отвечает за «холст», на котором модель будет рисовать, только пока ещё в своём внутреннем, невидимом виде. В этом блоке задаются ширина, высота и, при необходимости, количество картинок за один запуск.
Проще всего представить так, что вы не сразу рисуете финальное изображение, а сначала создаёте заготовку из «шума» нужного размера.
Проще всего представить так, что вы не сразу рисуете финальное изображение, а сначала создаёте заготовку из «шума» нужного размера.
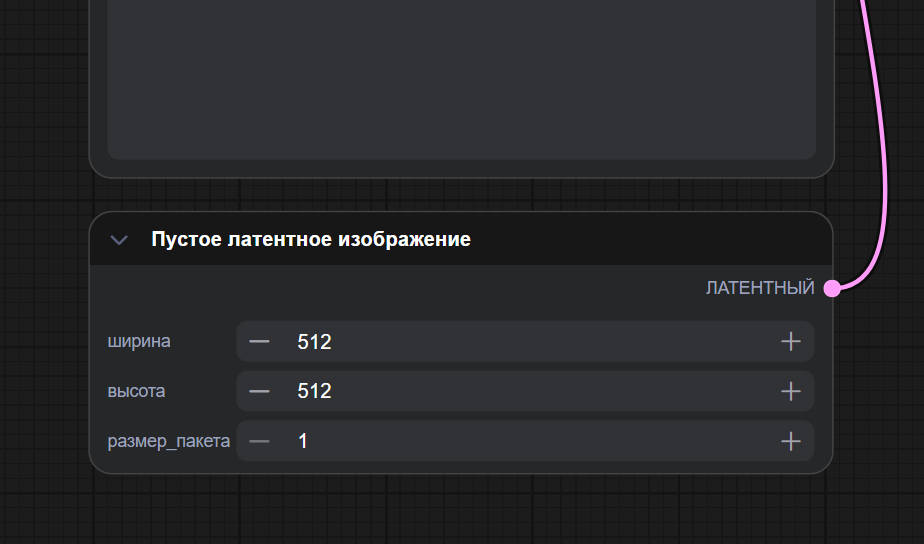
От того, какие значения вы поставите в Empty Latent Image, зависит формат будущего баннера или обложки и нагрузка на компьютер
Текстовые блоки prompt / negative
Содержание этих блоков — это «то, что вы говорите модели делать» и «то, что ей делать нельзя».
Так в блоке prompt вы описываете, какую сцену хотите увидеть: кто на картинке, в каком стиле, с каким настроением.
Блок negative делает обратное: туда вы вписываете, чего не хотите — размытости, лишнего текста, странных лиц, мусорных деталей.
Так в блоке prompt вы описываете, какую сцену хотите увидеть: кто на картинке, в каком стиле, с каким настроением.
Блок negative делает обратное: туда вы вписываете, чего не хотите — размытости, лишнего текста, странных лиц, мусорных деталей.
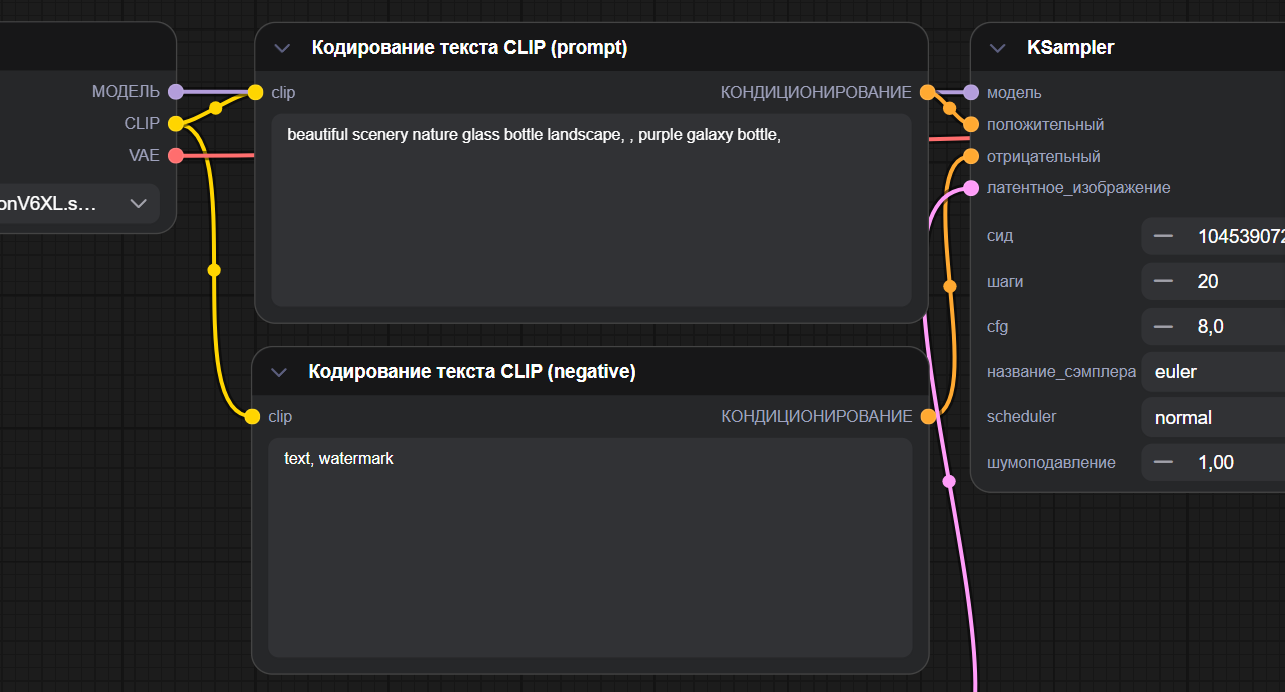
Модель учитывает оба списка одновременно, поэтому даже новичок быстро чувствует разницу: меняете формулировку или добавляете лишний запрет — меняется итоговое изображение
Итак, на этом шаге мы определили модель и LoRA, учли размер холста и что на нем должно быть изображено, то есть это те самые блоки, где пользователь задает вводные данные, а далее идет магия генерации от ИИ.
KSampler
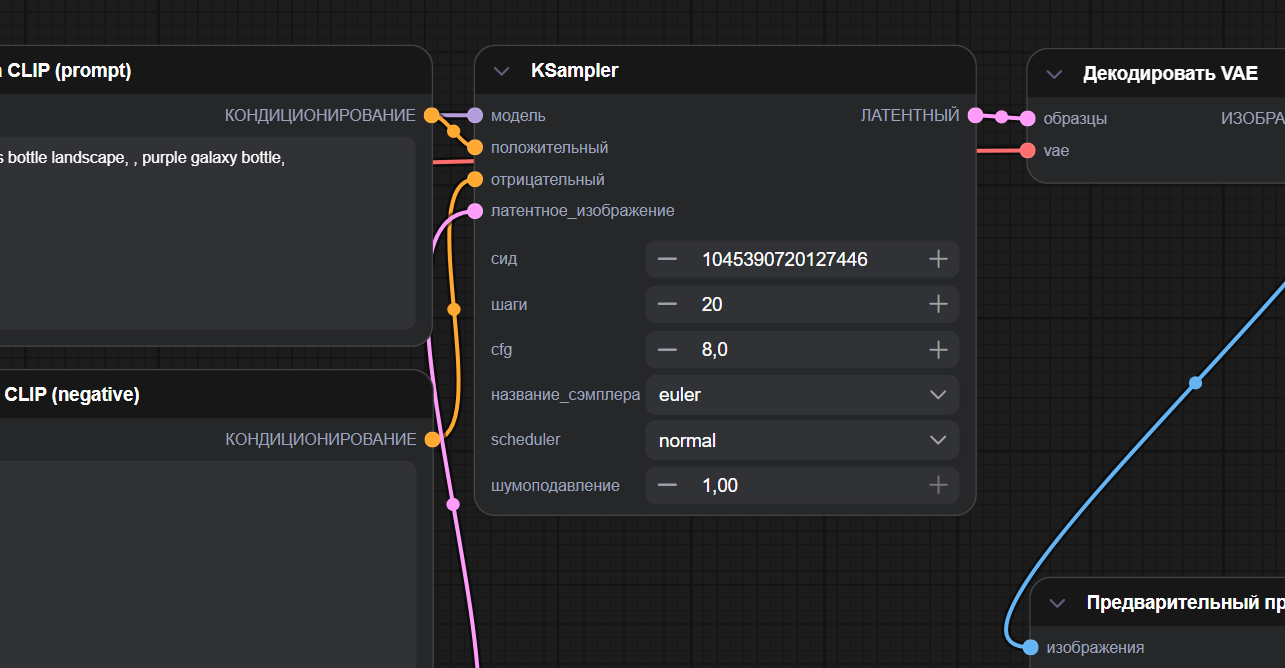
Переходим с вами к непосредственной генерации изображения и первый блок — он же «двигатель» генерации, который шаг за шагом превращает шум из Empty Latent Image в осмысленную картинку.
Он получает на вход модель, текстовые описания и размер холста, а дальше несколько раз проходит по изображению, каждый раз уточняя детали.
В этом блоке обычно настраивают три вещи, которые новичку достаточно знать:
Он получает на вход модель, текстовые описания и размер холста, а дальше несколько раз проходит по изображению, каждый раз уточняя детали.
В этом блоке обычно настраивают три вещи, которые новичку достаточно знать:
- количество шагов — чем их больше, тем детальнее, но дольше считается;
- силу привязки к тексту (CFG) — насколько строго модель должна следовать промпту;
- случайное число (seed) — позволяет либо повторить удачный результат, либо получить новый вариант сцены.
VAEDecode
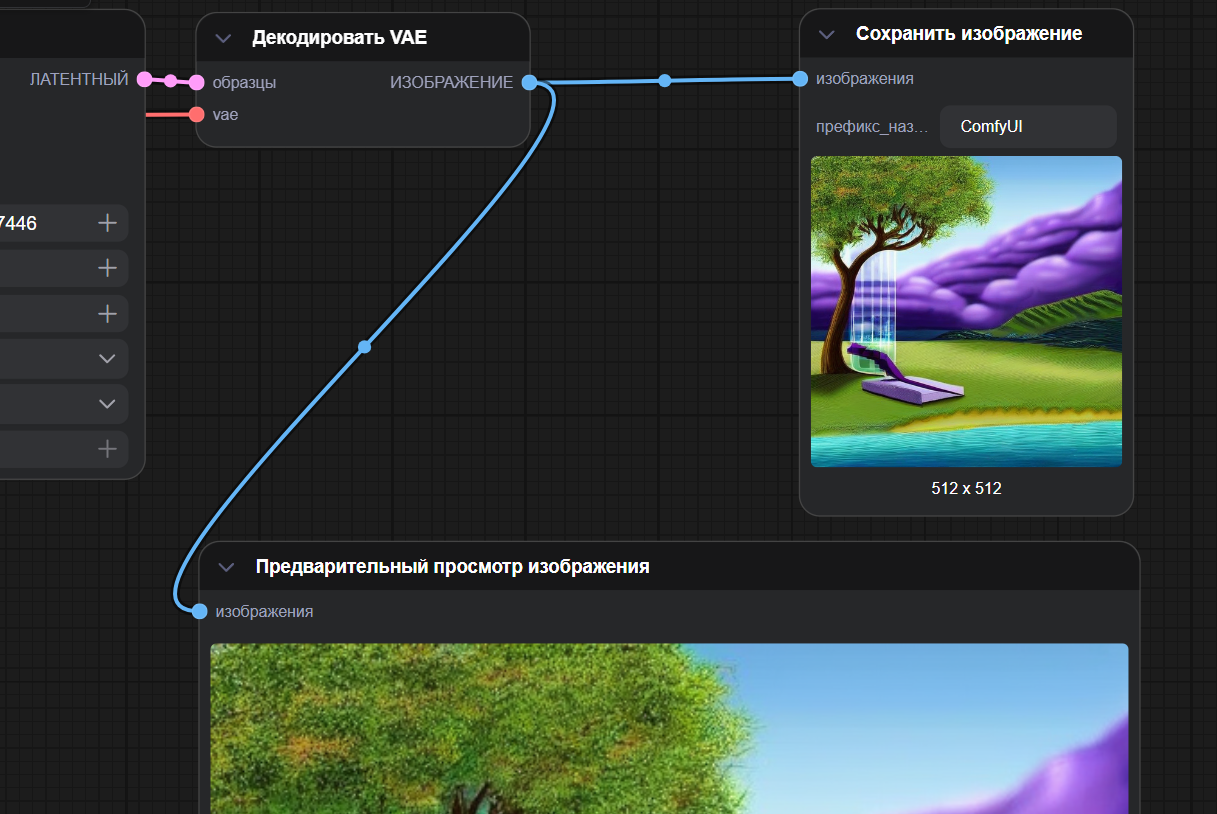
Блок, который переводит внутренний результат модели в обычное изображение, понятное человеку и любому редактору. Модель работает не с «картинкой как есть», а с сжатым скрытым представлением (латентом), и именно VAEDecode распаковывает этот латент обратно в формат RGB.
Без этого шага на выходе вы бы видели только набор чисел, а не готовый баннер или обложку. Поэтому цепочка всегда идёт так: KSampler дорабатывает латент → VAEDecode превращает его в картинку, которую уже можно просматривать, сохранять и дорабатывать дальше.
Без этого шага на выходе вы бы видели только набор чисел, а не готовый баннер или обложку. Поэтому цепочка всегда идёт так: KSampler дорабатывает латент → VAEDecode превращает его в картинку, которую уже можно просматривать, сохранять и дорабатывать дальше.
Preview Image
Данный блок показывает результат генерации прямо внутри ComfyUI, без похода в папки и поиска файла.
Как только цепочка дошла до этого блока, вы сразу видите картинку в интерфейсе и можете тут же решить: перегенерировать, поправить текст, поменять настройки или сохранить результат.
Как только цепочка дошла до этого блока, вы сразу видите картинку в интерфейсе и можете тут же решить: перегенерировать, поправить текст, поменять настройки или сохранить результат.
Для новичка это самый удобный способ учиться на экспериментах
Меняете пару слов в промпте или параметр в KSampler — снова запускаете схему и сразу видите разницу на экране, не забивая диск десятками лишних файлов.

Такой набор даёт ровно то, что нужно новичку: понимание, где выбирается модель, где текст, где размер, где сама генерация и где результат.
Почему это хорошая база для роста
Эта схема — рабочий «минимум», где из текста рождается картинка с учётом выбранного стиля LoRA и понятным предпросмотром. Она не перегружена ControlNet, масками, апскейлами и видеоузлами, которые только путают на старте.
Но при этом к этому «скелету» легко пристраивать новые части:
Но при этом к этому «скелету» легко пристраивать новые части:
- добавить Save Image, чтобы складывать удачные варианты в папку;
- вставить узлы апскейла после VAEDecode для увеличения и улучшения;
- подключить ControlNet, когда появится запрос на жёсткий контроль композиции или позы;
- дописать ветку для img2img или inpaint, когда станет понятно, как работает базовая прямая цепочка.
Именно поэтому такой рабочий процесс удобно использовать как обучающий, ведь он даёт прочный скелет, на который потом можно навешивать всё остальное, не теряя ориентацию в том, где проходит основной поток данных.
На этом серию можно честно считать закрытой, давайте подведем итоги.
Мы разобрались, как установить систему, как запускать готовые шаблоны и как собирать свои workflow под конкретные задачи, не утопая в настройках.
В качестве домашки предлагаем доработать наш текущий шаблон: добавить ещё один модуль с референс‑картинкой, которая будет так же влиять на результат, как модель и LoRA, и прикрутить апскейл, чтобы каждое сгенерированное изображение автоматически проходило через улучшение и увеличение разрешения.
И помните, что в современных реалиях такие инструменты на базе ИИ позволяют не только сэкономить часы рутинной работы, но и заметно поднять уровень визуала, а что делать с этой возможностью дальше — решать уже вам.
Мы разобрались, как установить систему, как запускать готовые шаблоны и как собирать свои workflow под конкретные задачи, не утопая в настройках.
В качестве домашки предлагаем доработать наш текущий шаблон: добавить ещё один модуль с референс‑картинкой, которая будет так же влиять на результат, как модель и LoRA, и прикрутить апскейл, чтобы каждое сгенерированное изображение автоматически проходило через улучшение и увеличение разрешения.
И помните, что в современных реалиях такие инструменты на базе ИИ позволяют не только сэкономить часы рутинной работы, но и заметно поднять уровень визуала, а что делать с этой возможностью дальше — решать уже вам.

Когда понятно, но всё равно сложно — приходите
Запишитесь на консультацию: разберём вашу ситуацию и подскажем, какой путь будет эффективным именно для вас.
Вы можете связаться с нами любым удобным способом:



